Converting Wide Dataset to Long Format
Converting Wide Dataset to Long Format
Completed by Kathy Anh Lam
November 8, 2020
At times, we may encounter datasets that have numerous data columns with the same set of data values. For example, in the file applemobilitytrends-2020-09-26.csv taken from https://covid19.apple.com/mobility, there are many data columns for each date, as shown in the image below.
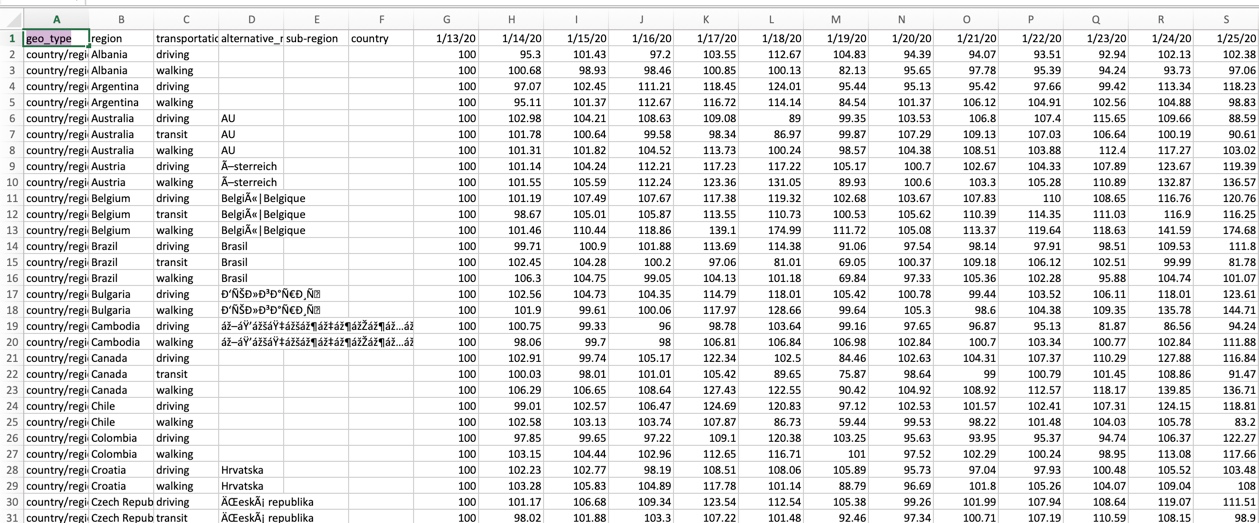
In this case, for better analysis, you might want to condense the dataset by moving all the different data columns into a single new column called ‘date’. This can be done by converting this wide set dataset into a longer formatted file. This blog post will guide you step by step to how to convert a wide dataset into long format.
Steps Taken:
-
First, download the necessary packages in your R Studio. This consists of readr and tidyverse.
install.packages("readr")install.packages("tidyverse")
Load the package with:library(readr)library(tidyverse) -
Read the data file of interest using the
read_csv()function from the readr package instead ofread.csv(), as this function handles datasets that consist of columns beginning with numbers more appropriately. The main difference betweenread.csv()andread_csv()is thatread.csv()imports a regular R data frame whileread_csv()creates a tibble. Tibbles are types of reading frames that are able to load faster, allow columns in datasets as lists and non-standard variable names, and do not change input types create row names. It is good practice to also assign the file once it is read. For example:
wide_data <- readr::read_csv("data/raw_data/filename.csv")
- Next, covert the dataset from wide form into long form with the
pivot_longer()function from the tidyr package. Again, it is good practice to assign the file once it is changes. This should look like this:
long_data <- wide_data %>%
pivot_longer(cols = starts_with("7")),
names_to = "date",
values_to = "rel_mobility")
The cols= starts_with("7") is an example of the starting column number that you would like to being to condense by pivoting. In this example, column 7 of my dataset is where the first date column starts. The names_to = "date" is assigning the the column label. In this example, I would like to condense all my columns after column 7 into a single column labeled “date”. The values_to = 'rel_mobility' is assigning the new values that are being condensed. In this specific example, the dataset I used was analyzing at relative mobility during each date.
- Finally, save the longer formatted file into a csv file in your designated output folder that is named based on the input but has “_longer” added on before .csv suffix. This can be done with:
basename_no_ext <- tools::file_path_sans_ext(basename(wide_data))
file_name <-(paste0("output/..../", base name_no_ext, "_long.csv")
readr::write_csv(long_data, path = file_name)
return(long_data)
The result should look like this:
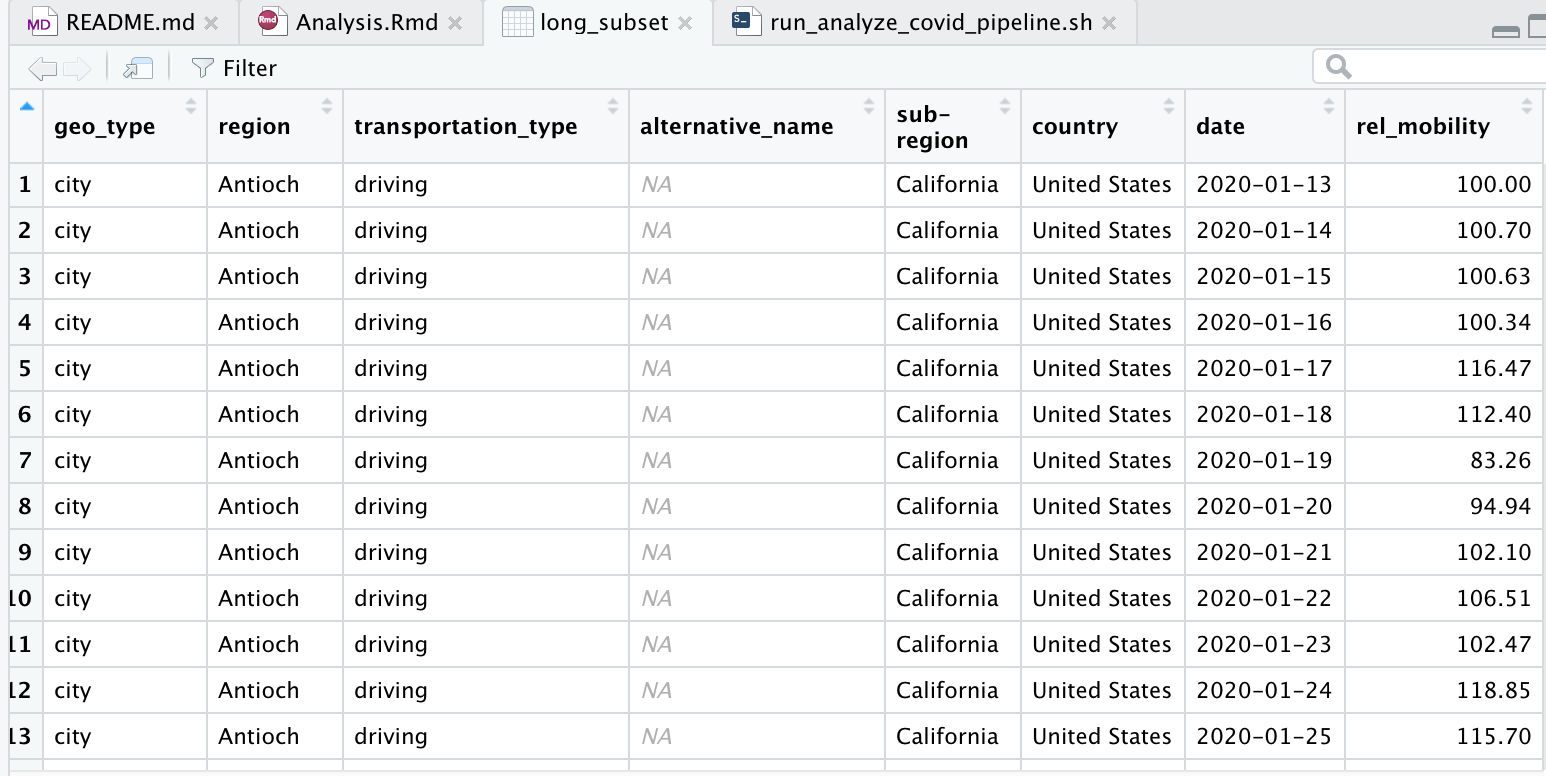
If you plan on converting more datasets from wide format to long in the future, you can also create one whole function that includes all the functions (readr::read_csv(), tidyr::pivot_longer(), readr::write_csv(), etc.) mentioned above. For good practice, I also recommend testing out the function at the very end of your R script to see if the output file is properly created. It is also good to note that the tidyr package also includes the pivot_wider() function to do the reverse of pivot_longer().
For more information on how to create a function and use them, make sure to check out Jaclyn’s blog post in this repository.