Ten Tips for Tidy Data
Why use tidy data?
So, you’re beginning to explore the wonderful world of bioinformatics! There is an incredible amount of computations and analytics you can accomplish with even just basic bioinformatics tools. However, all of these tools rely on a reliable organization of tabular data (spreadsheets) in order to do what they’re intended to do and avoid major errors. This is what is known as Tidy Data! Ensuring the use of tidy data not only prevents errors in data analysis, it also facilitates effective communication among collaborators. Below, I’ve laid out ten basic principles of tidy data. By using these principles, you’re setting up a strong foundation to make solid, clear, and reproducible analyses in the future.
10 Tips for tidy data
1. Organization
At the very core of tidy data principles is the organization of tabular data in the following way:
- Each variable forms a column
- Each observation forms a row
- Each type of observational unit forms a table
This seems like a very simple concept, but there are some very common mistakes that violate this structure.
One very common problem is using column headers that are values instead of the name of a variable. In the example below, each cell contains an observation, but the column header, the date of the observation, is in fact another observation, that should have its own column.
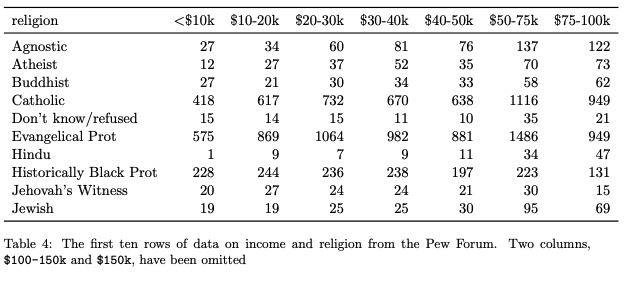
It should be re-organized so that the date is in its own column, and the column headers are descriptive, but don’t store any data themselves.
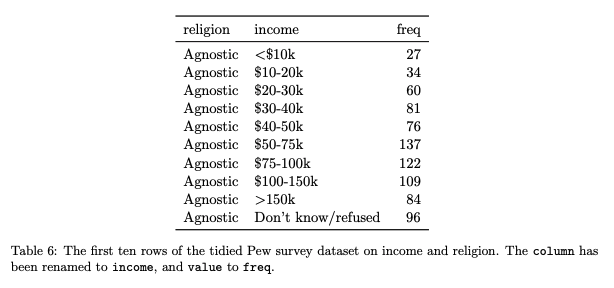
2. Be consistent.
It is very important to be consistent. Whatever you do, keep it consistent. This is especially important when working with collaborators, but it also helps you with comparisons and analysis, and is increasingly important the larger your dataset. This rule is crucial to preventing errors. Choose a format and stick to it throughout your dataset. It may help to have comments or a data dictionary to remind yourself of your format. Examples of being consistent include:
- Use consistent variable names (“leaf_number” vs. “num_of_leaves”)
- Use consistent codes for categorical variables (“female” vs. “F”)
- Use a consistent code for any missing values (“NA” vs. “—” vs. a blank cell)
3. Date format
Dates should be formatted using the global ISO 8601 standard which is YYYY-MM-DD. For example, 2020-11-06 is November 6th, 2020. This is standard and helps to avoid confusion between collaborators of different countries. Beware the automatic date formatting that happens in excel!
4. Choose good names
In general, think carefully about how you name things. This applies to both file names and column names. They should be descriptive enough to avoid confusion, but concise enough to be functional. As a general rule, do not use spaces or other special characters in file or column names, except for underscores or hyphens. And of course, think about Tips #2 and #3 when naming things.
5. No empty cells
It is generally accepted to use “NA” when a cell is meant to contain no value. This makes it clear that the cell was not left blank by mistake. And this will come in handy later, when sorting or manipulating data, to know the common code for a missing value.
6. Just one value per cell
During data collection, there may be reason to store multiple, related data values in the same cell. Perhaps a code identifying an individual, that contains two pieces of information about that individual (like “adult_male_01”) or two related measurements (like “length x width”). But, in a tidy spreadsheet, these should be treated like two distinct pieces of data and split into different columns accordingly. In the future, you may want to sort or compare your data by these different variables, and you’ll be glad you split them.
7. Make it a rectangle
Your spreadsheet should be organized into a single rectangle with rows corresponding to subjects and columns corresponding to values. Often, data is not collected this way. But if you’re able to combine it into one rectangle, your computing and analysis steps will be much more streamlined.
8. Do not use font color or highlighting as data
It may be tempting to utilize all the color and visualization tools that programs like Excel offer to display information visually. For example, highlighting certain cells where the values are uncertain or using fonts to distinguish values in some way. But when you begin to analyze the data, it can be really difficult to extract that information for use in an analysis. Any important information should be stored in a way that is plain text readable. If you were to take away any color or font formatting, would all of that information still be clear?
9. Save data in plain text file
Keep a copy of your data in a plain text, comma or tab-delimited format. The most common is to use CSV files. These spreadsheets lose all the formatting that something like Excel offers, but it can be opened in any spreadsheet program, and it is easier to deal with in coding programs. Not only will it simplify your code, but the nonproprietary format makes your data more accessible to any collaborator, and also to your future self.
10. Avoid calculations in raw data files
It is very common to see the use of spreadsheet programs like Excel to make calculations. Generally, this should be avoided. Going into a data file to make calculations carries a risk of making mistakes or making unintentional changes to the data. It’s a good idea to have a raw data file that contains just that; no calculations or graphs. It is a good idea to write-protect and back up these files, so the integrity of the data stays intact, regardless of whatever analyses happen later on. If simple calculations are included as formulas in your spreadsheet, be sure to copy and paste the values into their own cells, so they are saved as independent numbers instead of formulas.
What to do with tidy data?
It may take extra work to tidy up your data, and make sure your spreadsheets are organized, but when you begin trying to analyze your data, you will be glad you took the extra time. From here, there are many different tools and functions to filter, transform, sort, aggregate visualize, and model your data. By adopting these principles of tidy data, you reduce your chances of errors and increase ease of collaboration and reproducibility.