Best Practices for Spreadsheet Data!
Written by: Naailah Trejo
The Importance of Organizing Spreadsheet Data
Spreadsheets, such as Microsoft Excel, are often used by researchers in order to keep track of important experimental observations and results. Spreadsheet data entry in the laboratory is often formatted in a way that can be easily visualized by the human eye. However, this formatting is not ideal when the data needs to be analyzed by a programming language, such as R. One of the key advantages of organizing spreadsheet data is that computer programs can easily interpret and parse through the data in order to analyze it. In the next section, I will discuss some best practices for formatting spreadsheet data by hand that is both human readable and machine readable, specifically for R.
Before You Begin
- Make a duplicate of the raw data
You should never directly edit the raw data given to you. Instead, you should create a copy of the original spreadsheet and place it into a ‘cleaned’ data directory. From here, you can edit this duplicate spreadsheet directly. This step allows you to refer to the original spreadsheet if there is a discrepancy in the data. - Keep a record of your analysis
It is important to create a plain text file, that is stored in the same directory as the data file, in order to document what is being done to the spreadsheet data. After data cleaning and analysis, you often end up with a spreadsheet that looks very different from the original. Recording your steps will allow anyone to reproduce your analysis.
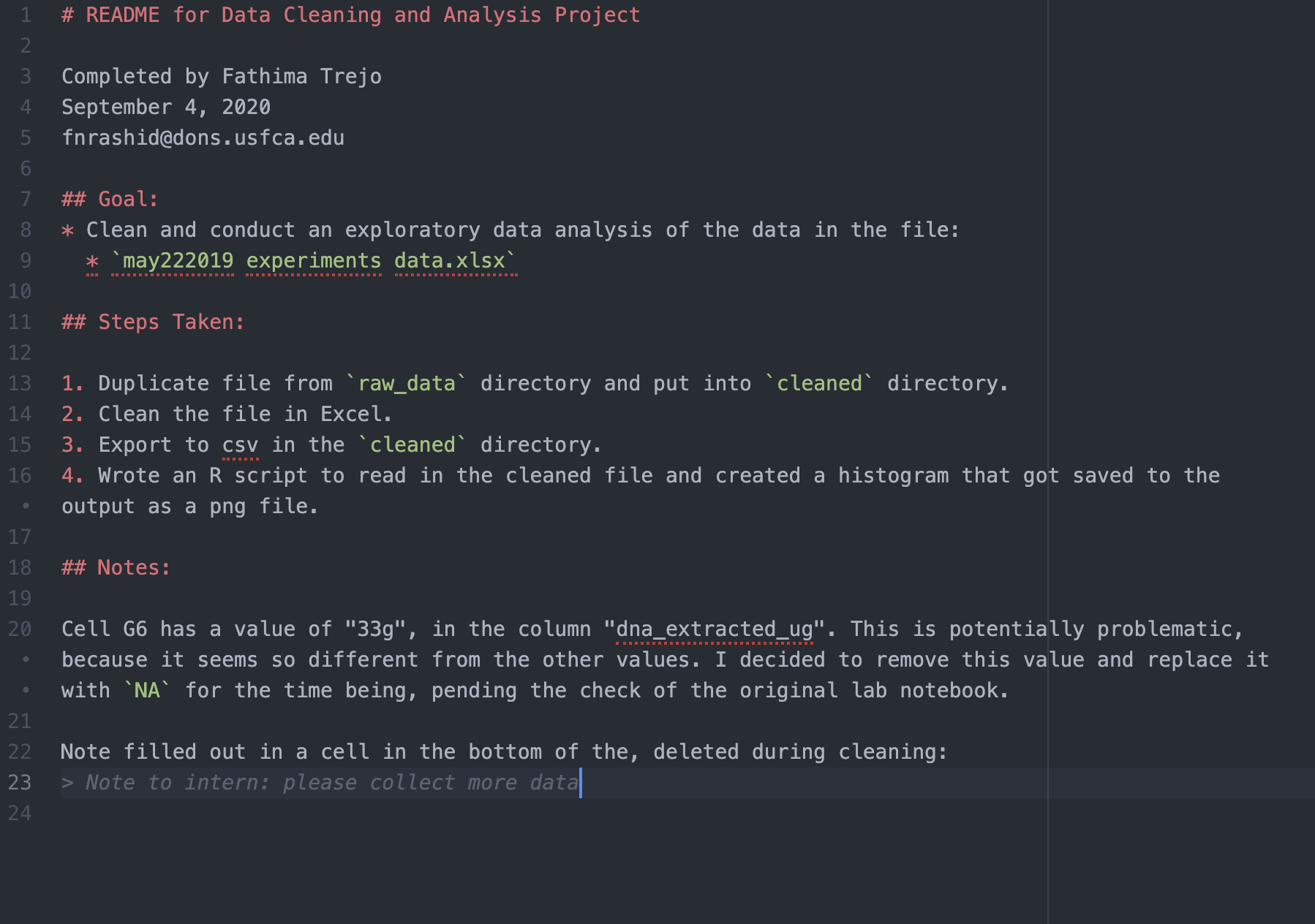
Here is an example of a README.md file that was used to document the steps taken to clean a spreadsheet:
Key Principles for Tidying Data in Excel by Hand
- Formatting
- It is essential that all variables (the things being measured) are placed in columns, while individual observations are placed rows.
- Sometimes the spreadsheet will not be in a rectangular format, but instead data will be placed randomly in cells. In R, all of the columns need to have the same number of rows. If they do not, R will fill in empty cells with NA and give you inaccurate results.
- It is also helpful to delete a handful of empty cells underneath the dataset, as well as some empty columns to the right of the dataset. If there was previous content in any of these cells, Excel will add empty rows or columns onto the spreadsheet when it is exported as a CSV.
- Variable titles
- Variables names, such as column names, should be lower case and contain no spaces. You can replace spaces with underscores.
- Be descriptive and concise when naming columns, making sure no two columns have the same name.
- Avoid special characters such as $, @, #, *,(,), etc. These special characters often have a special meaning in programming languages and can be interpreted differently than expected.
- Column headers cannot start with a number in R. Column headers that begin with a number will get modified when being read into R. Instead write out numbers.
- i.e. Write second instead of 2nd.
- Record units in the column header instead of entering units into each cell separately.
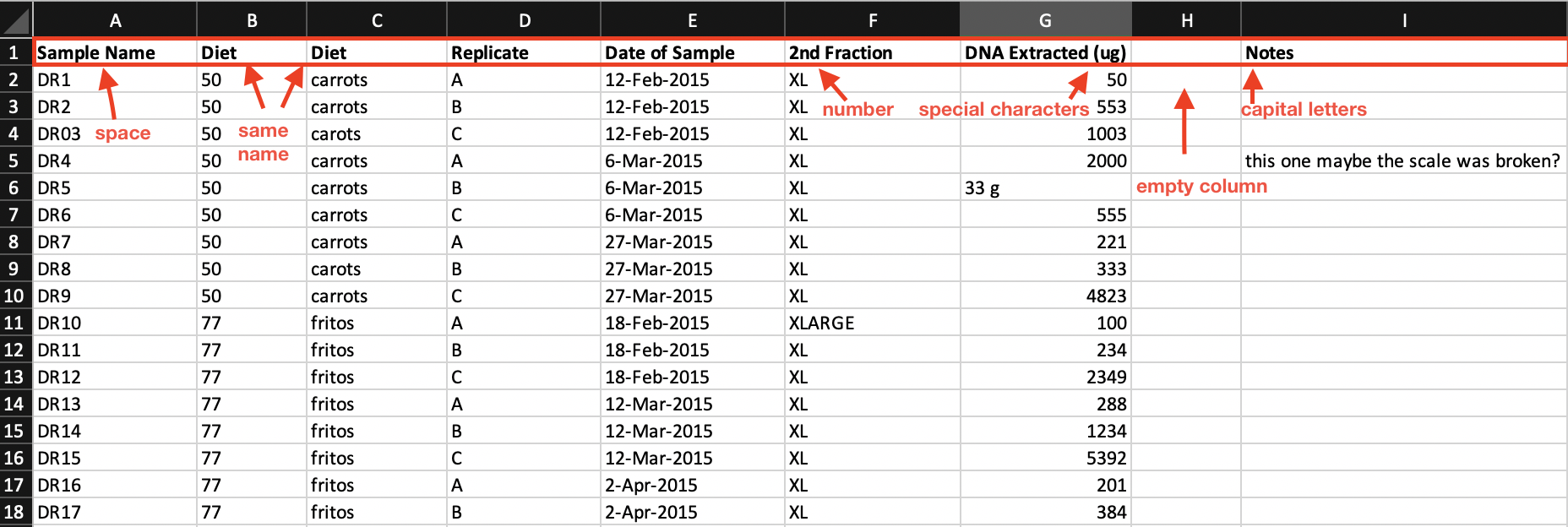
Here is an example of a spreadsheet with ‘dirty’ columns:
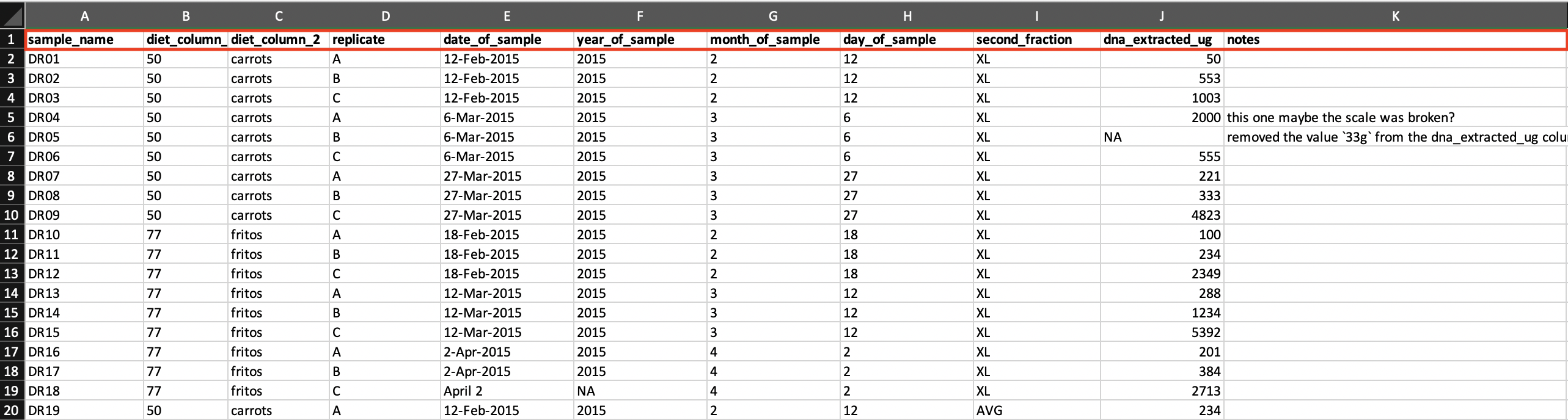
Now here is the above data set with ‘cleaned’ columns:
- Column content
- There shouldn’t be any empty columns in the data set. However, it is okay to have empty cells in the ‘notes’ column.
- For any cells that contain missing data, enter ‘NA’. In R, ‘NA’ represents a missing data value and will be read in appropriately. Do not write ‘N/A’. ‘N/A’ will be read in as a word not as a special character.
- Keep the data inside columns consistent. In other words, data that represents the same category have to be identical.
- i.e. Do not write ‘False’ sometimes and write ‘F’ other times. R will interpret them as different categories. Choose one or the other, not both.
- For R, every column must have the same type of data (ie. character, numeric, logical data type) in it.
- When entering data with a specific pattern, be careful not to include any extra spaces or forget leading zeroes in the recorded data.
- i.e. In the list: ‘DR8, DR09, DR10, DR11’; ‘DR8’ should be written as “DR08’, if the the scheme contains four variables. Otherwise the data will not be parsed out appropriately in R.
- Dates should be written using the ‘ISO 8601’ standard, YYYY-MM-DD, and should be stored in plain text format. If not done so, Excel will store dates as an integer internally.
- i.e. November 1, 2020 should be written as 2020-11-02
- Another way to record dates in Excel is to create three separate columns for ‘year’, ‘month’, and ‘date’, and again store these columns in plain text format. By doing so, Excel will store the data as ordinary numbers.
Here is an example of three separate columns for ‘year’, ‘month’, and ‘date’ in an Excel spreadsheet:
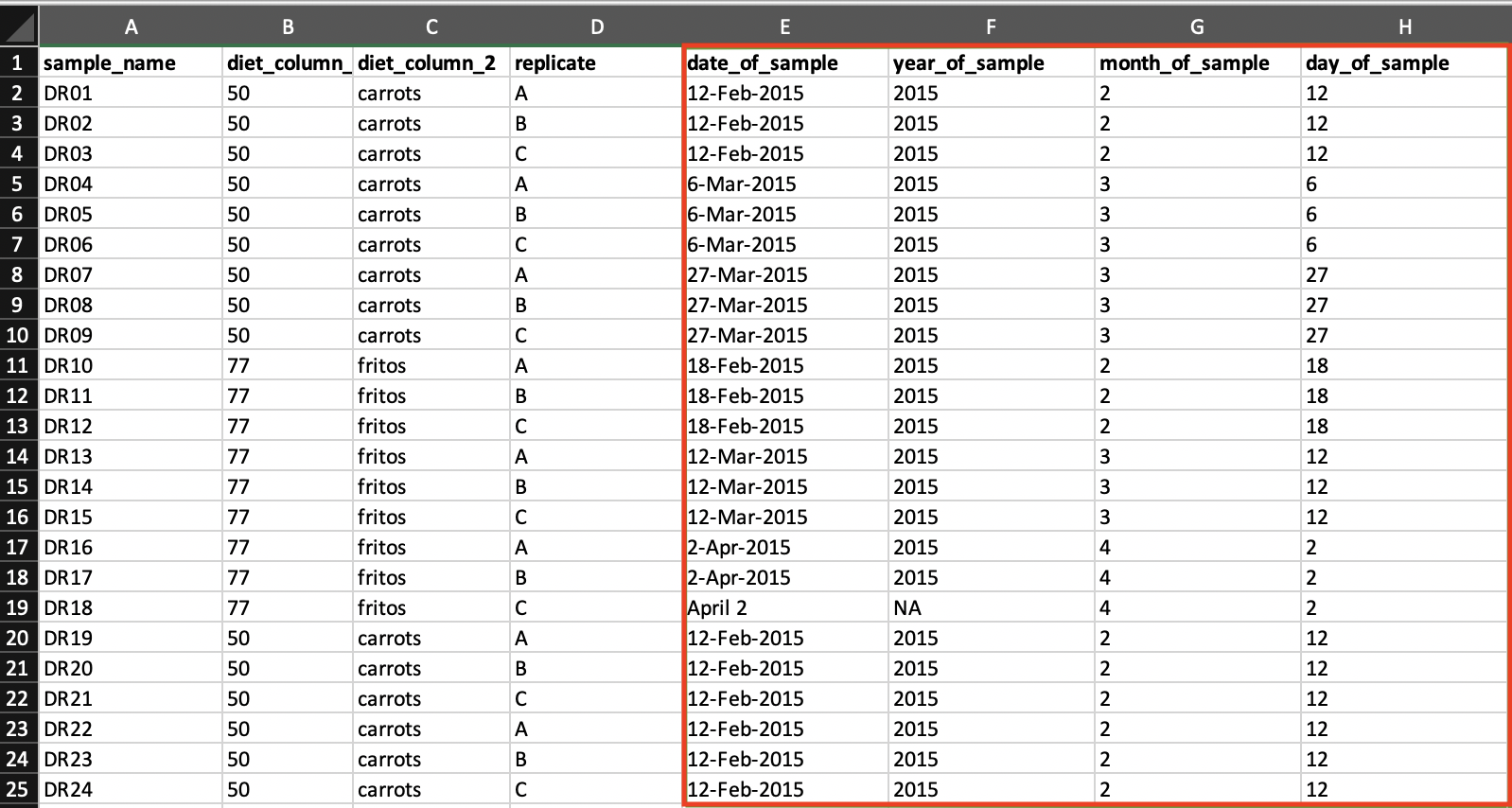
- The ‘notes’ column
- It is a best practice to include a ‘notes’ column in the spreadsheet because it will not be separated or lost from the data set.
- This column is used to attach any important comments to the data set and can be referenced later.
- Any new entries in the notes column should also be recorded in the plain text file (ie. README.md).
- It is important to look for comments in the ‘notes’ column pertaining to inconsistencies in the recorded data. If the recorded data cannot be trusted, it should not be left in the spreadsheet when it is being analyzed. Instead inconsistent data should be replaced with ‘NA’ and a note should be written describing why it was removed. If uncertain data is left in the spreadsheet it could lead to inaccurate results.
Exporting the Cleaned Dataset
After tidying up the spreadsheet, you want to export it as a CSV file so it can be analyzed by R. Converting the Excel spreadsheet to a CSV will also allow anyone to use the data.